

Introduction
Over the last decade, System Design interviews have evolved significantly.
The first wave focused on distributed systems: designing high-throughput, fault-tolerant services like ride-sharing platforms, messaging systems, and video streaming architectures. The second wave introduced ML System Design, where engineers were expected to reason about data pipelines, feature stores, model training infrastructure, online serving systems, and experimentation frameworks.
Today, we are entering a third wave.
Organizations are increasingly building systems that can reason, plan, use tools, maintain memory, and iteratively execute tasks. These systems don’t simply generate static text outputs-they take autonomous actions in real development environments. This has given rise to a new category of engineering problems: Agentic System Design.
Unlike traditional software systems, agentic systems operate through tight feedback loops. They observe their environment, execute actions, evaluate outcomes, and dynamically adapt their behavior.
In this article, we’ll explore one of the most prominent examples of this new paradigm: Designing an Autonomous Coding Agent. We will approach it exactly how you should in a senior-level system design interview-starting with the core mental shifts, mapping requirements, breaking down the high-level architecture, and tackling deep production trade-offs.
How to Approach This Problem
When an interviewer asks you to “Design a Coding Agent,” they are not asking you to build a wrapper around an LLM chat endpoint. They want to see if you can engineer a stable, deterministic framework around a fundamentally non-deterministic core.
Before diving into boxes and arrows, explicitly establish the four pillars that separate agentic designs from traditional software engineering:
Loops over Pipelines: Traditional systems follow a predictable Request→ Response flow. Agentic systems operate in an execution loop: Task →Plan →Act → Observe →Adapt →Retry
Active Tool Utilization: The agent is given leverage over its environment. It interacts with the outside world via structured APIs to read files, run test suites, execute shell builds, and manage git repositories.
Non-Deterministic Outputs: The same exact prompt can yield varied code paths. Because of this, code cannot be blindly trusted; it must be programmatically verified.
Silent Failure Modes: A semantic error or retrieval mistake can generate code that compiles flawlessly but solves entirely the wrong problem. Observability and automated evaluation are core architectural requirements, not afterthoughts.
Clarifying Questions to Narrow Scope
A strong candidate establishes the guardrails before designing. In an interview, explicitly call out these scoping vectors:
Scope of edits: Are we supporting single-file bug fixes or massive multi-file refactoring across a repository?
Autonomy level: Is this fully autonomous or human-in-the-loop for every key decision?
Scale & Repository Size: Are we targeting small standalone microservices or a massive codebase?
Environment Constraints: What languages, build tools, and security boundaries are enforced?
High-Level Architecture
A common interview pitfall is drawing a linear pipeline. A production-grade coding agent must be structured as a state machine where verification results continuously feed back into the execution layer.
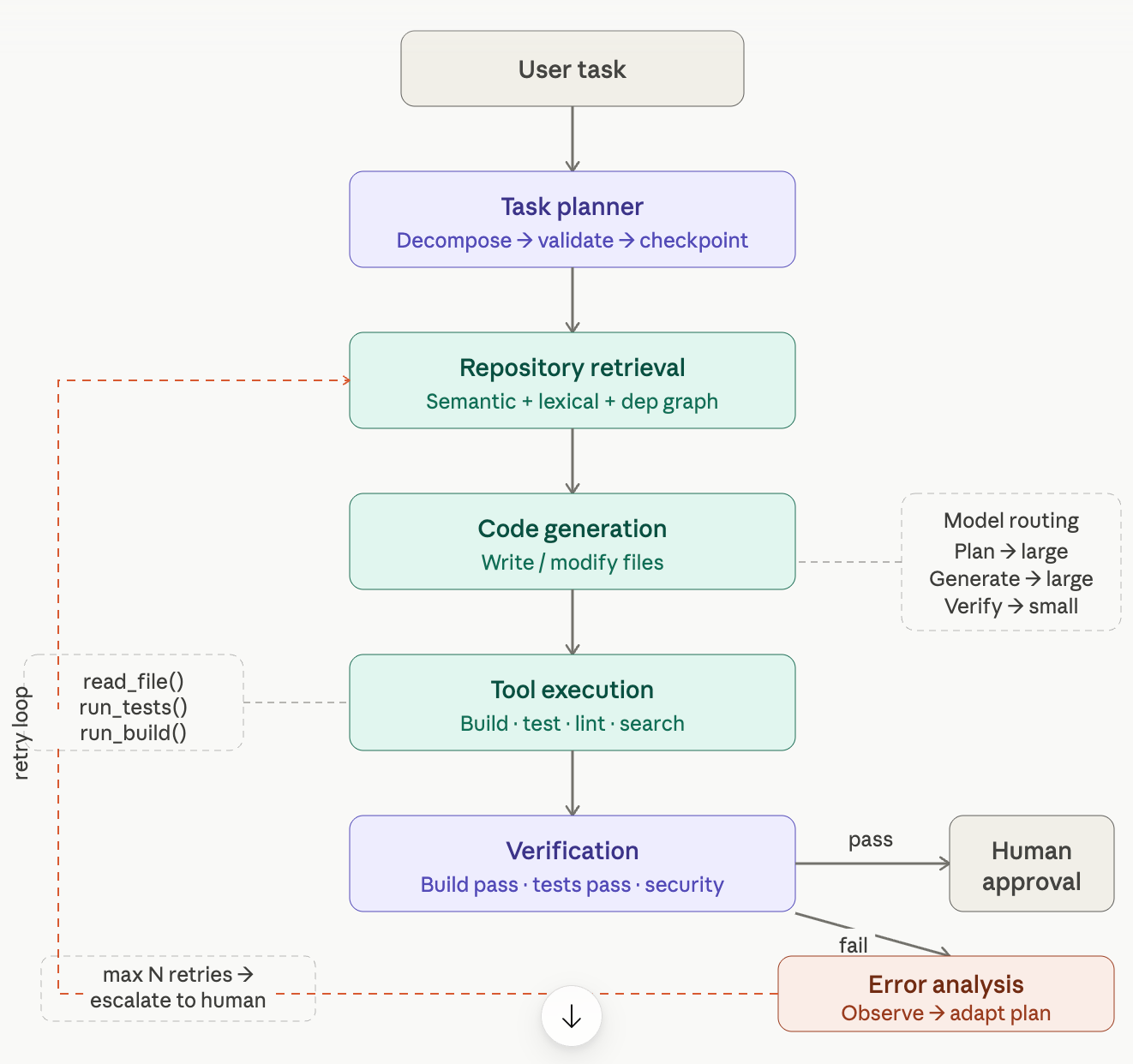
Walkthrough: “Add a ‘Remember Me’ Feature”
To visualize how these abstract components interact, let’s trace a straightforward feature request through the entire system architecture.
The Objective
User Input: “Update the login function to support a ‘Remember Me’ checkbox. If checked, extend the session cookie expiration to 30 days instead of the default 24 hours.”
Target Stack: A standard Node.js/Express authentication service.
1. The Planning Phase
The Task Planner breaks down the user request into explicit, manageable engineering steps.
[Generated Plan]
Step 1: Locate the file handling user login and session cookie creation.
Step 2: Parse the new `rememberMe` flag from the incoming request body.
Step 3: Modify the cookie configuration logic to apply the conditional 30-day expiration.
Step 4: Run the authentication unit tests to verify the changes.
2. The Context & Retrieval Loop
Instead of reading the whole codebase, the agent queries the Repository Understanding Layer:
Lexical Search looks for strings like
res.cookie(orloginController.Semantic Search searches for “session expiration” or “auth cookies”.
The system returns two highly specific files: src/controllers/authController.js and src/tests/auth.test.js.
3. Execution & Tool Interaction
The Execution Agent picks up the first steps of the plan and uses its toolset inside an isolated sandbox.
1.Environment Probe:Tool: Read File.
The agent reads src/controllers/authController.js to see how cookies are currently issued. It finds a standard line:
res.cookie('session_token', token, { maxAge: 86400000 }); (24 hours).2.Code Modification:Tool: Write File.
The agent updates the file to extract rememberMe from req.body and modifies the code to:
const duration = req.body.rememberMe ? (30 * 24 * 60 * 60 * 1000) : 86400000;res.cookie('session_token', token, { maxAge: duration });4. The Verification & Adaptation Loop
The agent passes control to the Verification Layer to run the local test suite.
[Verification Log]
Running: npm test
Result: FAILURE
Error: "ReferenceError: rememberMe is not defined at login (src/controllers/authController.js:12:3)"
The system captures this structured error output.
The agent looks at its own edit and realizes it made a classic copy-paste error: it used rememberMe directly in its conditional statement instead of pulling it out of the request body object (req.body.rememberMe) first.
Because this is an agentic loop, it doesn’t give up. It adapts its plan, rewrites the file with the missing destructuring statement (const { rememberMe } = req.body;), and reruns the tests. This time, the linter and test suite return a clean SUCCESS.
5. Human-in-the-Loop Review
The system bundles the entire run into a pull request for an engineer to inspect.
+------------------------------------------------------------+
| Pull Request: Add Remember Me support to login |
+------------------------------------------------------------+
| [Task Intent]: Extend session cookie to 30 days if checked |
| |
| [Execution Trace]: |
| - Read 1 file, modified 1 file |
| - Fixed 1 ReferenceError during verification automatically|
| |
| [Verification Status]: |
| - Linter: PASSED |
| - Unit Tests: 5/5 PASSED |
| |
| [Diff View]: |
| + const { username, password, rememberMe } = req.body; |
| + const maxAge = rememberMe ? 2592000000 : 86400000; |
+------------------------------------------------------------+
Deep-Dive: Core Components & Deep Trade-Offs
1. Repository Understanding Layer
To prevent context-window overflow and keep token costs manageable, the repository layer must index codebases hierarchically. To do this reliably at scale, a production system relies on four core indexing strategies:
Lexical Search: Best for finding exact symbol matches, specific configuration keys, or hardcoded variables. This is traditionally implemented using Elasticsearch or BM25 text indexing over precise code tokens.
Semantic Search: Essential for resolving high-level user intent when the exact structural keywords aren’t known (e.g., searching for “session expiration logic”). This relies on generating dense vector embeddings of individual code chunks.
Dependency Graphs: Crucial for tracking code relationships and mapping out the downstream blast-radius of a refactor. It maps imports and class inheritances, usually using a graph database.
Symbol Trees: Provides lightning-fast jumps directly to function definitions, callers, and callees by parsing the abstract syntax tree of the code via Tree-sitter or Language Server Protocol (LSP) integrations.
Trade-Off to Highlight: Hybrid vs. Pure Vector Retrieval. Pure vector semantic search often washes out distinct structural syntax (like specific variable definitions or configuration keys). A production system must implement hybrid search (BM25 + Dense Vectors) cross-referenced with an LSP graph to guarantee the agent actually follows the correct reference tracks.
2. Tool & Sandboxing Layer
An agent must never execute arbitrary code directly on your host infrastructure. The tool layer must enforce structured inputs and outputs while running inside a hardened sandbox.
Isolation Guardrails: All test executions, builds, and file system mutations happen within disposable environments like Docker containers or Firecracker MicroVMs with strict network and CPU limits.
Structured Outputs: System tools should never return raw, unstructured terminal streams. If a build fails, the tool should parse the output and return a clean JSON payload detailing the exact failure filename, line number, and stack trace category. This allows the LLM to target its fixes with high precision.
3. Dual-Tiered Memory Architecture
Short-Term Memory (In-Context): Tracks the live execution state machine. It contains the current active steps, the code diffs generated during this session, and recent terminal errors.
Long-Term Memory (Vector/Key-Value Store): Cross-session knowledge. It stores organizational code conventions, historical PR reviews where code was corrected by a human, and successful past patterns for similar tasks.
Operational Excellence: The Evaluation Framework
You cannot scale what you cannot measure. Evaluating an agentic system on final output code alone is a lagging indicator. You must track the efficiency of the journey through the agent loop.
Evaluation Metrics
│
┌─────────────────────────┼─────────────────────────┐
▼ ▼ ▼
[Task Success Rate] [Loop Efficiency] [Economic Cost]
• Build success % • Retry count per task • Tokens consumed per PR
• Unit test pass % • Time-to-completion • Infrastructure costs
• Human acceptance % • Pattern stagnation • Model routing efficiency
Task Success Rate: What percentage of generated code passes syntax validation, builds cleanly, passes local unit tests, and is ultimately accepted by a human reviewer without massive rewrites?
Loop Efficiency (Crucial Metric): How many retries did it take to succeed? A task that completes successfully after 2 iterations is highly reliable. A task that takes 19 iterations is experiencing stochastic drift and is on the verge of entering an infinite loop.
Cost and Latency Profiles: Tracking token-consumption density per successful task to prevent the agent from burning out the API budget on massive, cyclic contexts.
Structural Failures & Defensive Design
Infinite Retry Loops: The agent tries to fix a compilation bug, introduces a secondary error, tries to fix that, and ends up oscillating between two incorrect states.
Mitigation: Implement strict Execution Budgets (e.g., max 5 loops or max $2.00 token cost per sub-task) and auto-escalate to a human operator when budgets are breached.
Context Window Bleed: As the agent interacts with tools and runs multiple test suites, the short-term conversation context grows exponentially, causing the model to lose track of the core goal.
Mitigation: Apply aggressive context compaction and summary layers. Compress raw terminal logs into structured diagnostic summaries before piping them back to the planning model.
Unsafe Code & Security Anomalies: The agent imports third-party dependencies with security vulnerabilities or inadvertently writes code containing SQL injections or hardcoded credentials.
Mitigation: Treat the agent as an unverified external vendor. The Verification Layer must contain strict security gates (e.g., running Static Application Security Testing (SAST) tools like Semgrep or SonarQube) before triggering human review.
Architectural Differentiator: Standard vs. Senior/Staff Design
In a System Design interview, your seniority tier is judged entirely by where you focus your depth. A standard candidate focuses heavily on the intelligence of the LLM itself. A Senior or Staff-level candidate focuses on engineering a stable framework around a non-deterministic core.
+-------------------------------------------------------------------------+
| Standard Candidate Focus |
| - Building a basic request-response loop (Prompt -> Code Output). |
| - Expecting the model to magically hold the entire repo in context. |
| - Treating verification as a simple "pass/fail" script. |
+-------------------------------------------------------------------------+
▲
│ The Engineering Gap
▼
+-------------------------------------------------------------------------+
| Senior / Staff Candidate Focus |
| - Stateful, multi-step planning with dynamic adaptation loops. |
| - Hierarchical retrieval (LSP graphs + hybrid vector search). |
| - Isolated sandbox execution (Firecracker/Docker) with telemetry. |
| - Enterprise metrics: Token budgets, retry limits, and model routing. |
+-------------------------------------------------------------------------+
A Senior or Staff Engineer spends less time talking about the LLM’s raw capabilities and significantly more time discussing the infrastructure surrounding it how to safely isolate execution environments, optimize token spend by routing minor tasks to smaller models, and handle architectural failures like infinite loops and state stagnation.
Summary
Designing a coding agent is an exercise in building deterministic scaffolding around a non-deterministic processing engine. By treating the agent loop as an explicit state machine complete with hybrid retrieval, structured tool outputs, automated verification gates, and hard economic/execution budgets you can build an agentic system that safely, predictably, and effectively scales human capabilities.
The next frontier of system design isn’t just about handling traffic spikes or structuring tables; it’s about architecting systems that can think, execute, and heal themselves in production.