


Beyond the Hype: Unpacking the 5-Layer Generative AI Tech Stack
Discover the foundational technologies powering the Generative AI revolution, and the critical skills needed at each level to build, manage, and leverage AI.

Welcome to the World of Generative AI!
Generative AI is no longer a futuristic concept; it's here, transforming industries from creative arts and content creation to software development and scientific research. Tools like ChatGPT, Midjourney, and Sora are captivating the world, hinting at a vast, underlying technological infrastructure that makes this magic possible.
But for many, the 'how' behind this revolution remains a black box. What are the fundamental components that enable AI to create, write, and innovate? And more importantly, what skills do you need to truly engage with this groundbreaking technology and shape its future?
This post aims to demystify the Generative AI ecosystem by breaking it down into a clear, 5-layer tech stack. We'll explore each layer, highlighting its purpose, key components, and the essential skills you'll need to master it. Understanding this stack is the first crucial step towards building expertise in GenAI.
The Generative AI Pyramid: A 5-Layer Tech Stack
Think of Generative AI as a powerful edifice, built layer by layer, from the raw computing power at its base to the user-friendly applications at its peak. Each layer is dependent on the one below it, and each requires a distinct set of technologies and skills.
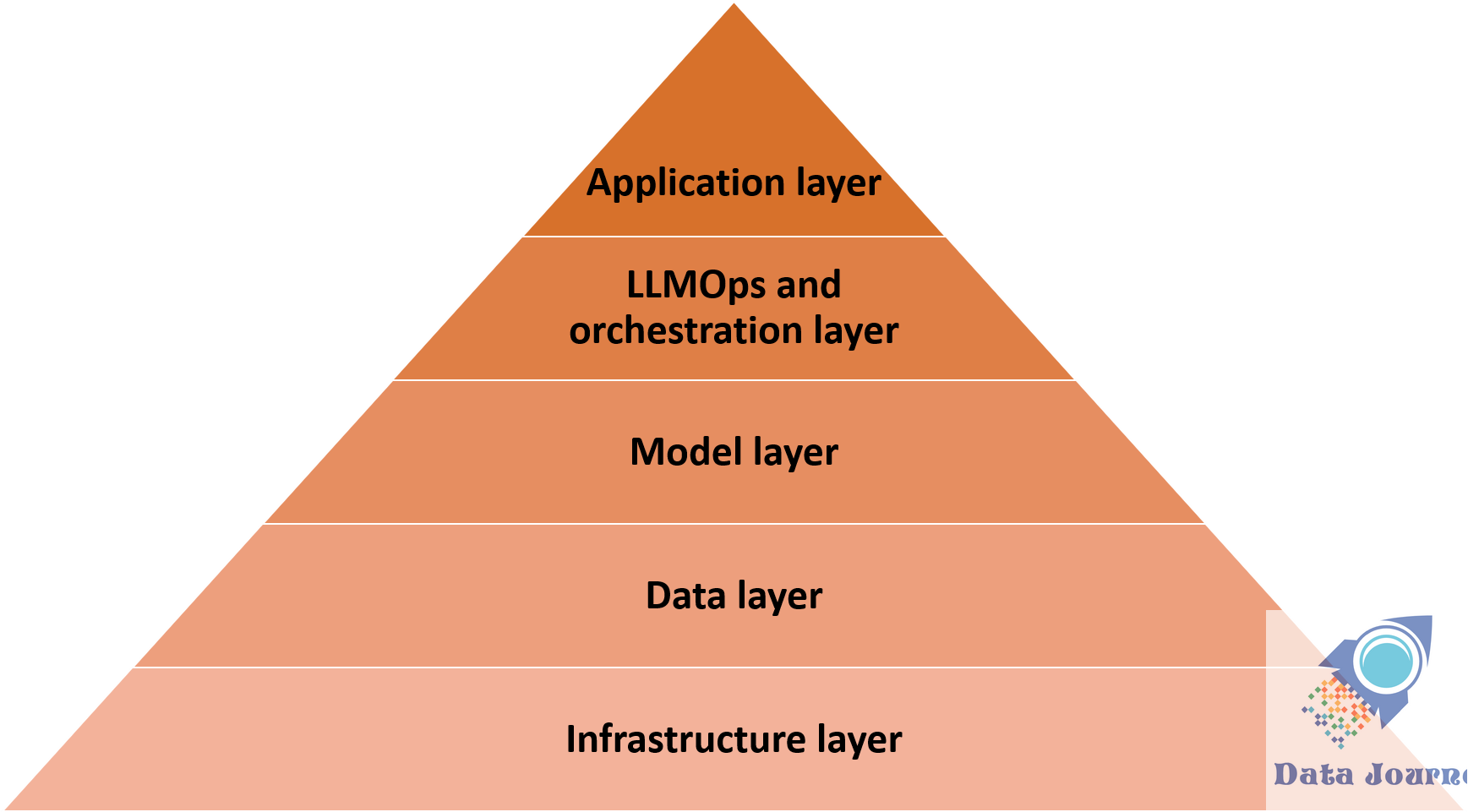
The Generative AI pyramid illustrates the hierarchical dependency of the tech stack, with foundational components at the base supporting increasingly abstract and user-facing capabilities towards the apex.
Let's explore each layer from the top down:
Layer 5: Application Layer
Purpose: This is the most user-facing layer, comprising the actual products and services that deliver Generative AI capabilities to end-users. It focuses on user experience, specific business logic, and presenting AI-generated content in a meaningful way.
Key Components & Responsibilities:
User Interface (UI) / User Experience (UX): Web applications (React, Angular, Vue.js), mobile apps (React Native, Flutter, Swift/Kotlin), desktop applications. This is what the user directly sees and interacts with.
Application-Specific Business Logic: Code that defines the unique features and workflows of the particular GenAI product. This includes user authentication, payment processing, integration with existing enterprise systems (CRM, ERP), and managing the overall application state.
User-Facing Prompt Logic: While core prompt engineering is lower down, the application might include logic for how user input is captured, how it's formatted for a prompt, and how the LLM's response is parsed and displayed to the user.
Agent Execution & Presentation: If AI agents are part of the application, this layer manages how the user interacts with the agent, triggers its actions, and how the agent's progress and final results are communicated back to the user.
User-Centric RAG Display: How the application presents retrieved context to the user (e.g., citing sources, showing retrieved documents) to enhance transparency and trust.
Examples: ChatGPT, Midjourney, GitHub Copilot, Jasper, enterprise chatbots, AI-powered content creation tools, intelligent virtual assistants.
Layer 4: LLMOps & Orchestration Layer
Purpose: This layer acts as the "nervous system" connecting the Application Layer to the core AI models and data. It handles the specific operational challenges of LLMs (LLMOps) and orchestrates complex AI workflows, including prompt management, RAG pipelines, and multi-agent systems.
Key Components & Responsibilities:
Prompt Engineering & Management:
Developing, testing, and optimizing prompt templates for various tasks.
Implementing prompting strategies (e.g., few-shot learning, chain-of-thought, self-consistency).
Versioning and managing prompts across different model versions and application features.
Retrieval-Augmented Generation (RAG) Pipelines:
Managing the entire workflow: processing user queries, retrieving relevant information from external knowledge bases (via the Data Layer), augmenting the prompt with retrieved context, and sending the combined input to the LLM.
Tools like LangChain and LlamaIndex are prominent here.
AI Agent Frameworks:
Implementing the core logic for AI agents: planning, tool use (e.g., via Model Context Protocol - MCP), memory management, and inter-agent communication (Agent-to-Agent - A2A).
Frameworks like AutoGen, CrewAI, and advanced capabilities of LangChain fall into this category.
LLM Serving & Inference Optimization:
Deploying and scaling LLMs for real-time inference.
Using specialized inference engines (e.g., vLLM, NVIDIA TensorRT-LLM, Hugging Face TGI) for high throughput, low latency, and efficient GPU utilization.
Handling request batching, quantization, and distributed serving.
LLMOps (Operational Aspects):
Experiment Tracking: Logging and managing LLM training, fine-tuning, and inference experiments (e.g., MLflow, Weights & Biases).
Model Deployment & Management: Versioning, rolling out, and rolling back LLM models and fine-tuned adaptations.
Monitoring & Observability: Tracking LLM performance (latency, throughput, token usage, quality metrics), detecting model drift, hallucination rates, and cost analytics.
Fine-tuning & LoRA Management: Orchestrating the fine-tuning process of base models with custom data, and managing different LoRA adapters.
A/B Testing: For different prompts, models, or RAG configurations.
Examples: LangChain, vLLM, AutoGen, MLflow, Weights & Biases, OpenAI/Anthropic/Google APIs (when used as part of an orchestrated flow), custom API gateways.
Layer 3: Model Layer
Purpose: This layer contains the core generative AI models themselves – the "brains" that perform the actual content generation, understanding, and embedding.
Key Components & Responsibilities:
Foundation Models (FMs) / Large Language Models (LLMs):
Pre-trained, general-purpose models on massive datasets that form the base for most GenAI applications.
Examples: GPT series (OpenAI), Gemini (Google), Claude (Anthropic), Llama (Meta), Mistral, Stable Diffusion (for images).
Fine-tuned Models: Specialized versions of foundation models that have been further trained on smaller, task-specific datasets to improve performance for particular use cases or domains.
Embedding Models: Models specifically designed to convert text, images, or other data into numerical vector representations (embeddings). These are crucial for RAG, semantic search, and other AI tasks.
Deep Learning Frameworks: Fundamental software libraries for building, training, and deploying neural networks.
PyTorch (flexible, research-oriented).
TensorFlow (robust, production-oriented).
JAX (for high-performance numerical computation).
Model Hubs & Repositories: Platforms for discovering, sharing, and versioning pre-trained models (e.g., Hugging Face Hub).
Examples: GPT-4o, Gemini 1.5 Pro, Claude 3 Opus, Llama 3, Stable Diffusion XL, OpenAI text-embedding-ada-002, PyTorch, TensorFlow.
Layer 2: Data Layer
Purpose: This layer provides and manages the massive datasets that are the lifeblood of Generative AI. It encompasses data collection, processing, storage, and organization for both model training and real-time inference contexts (like RAG).
Key Components & Responsibilities:
Data Collection & Acquisition: Sourcing raw data from diverse origins (web scraping, public datasets like Common Crawl, enterprise data lakes, user-generated content).
Data Preprocessing Tools:
Big Data frameworks (Apache Spark, Apache Hadoop) for cleaning, transforming, normalizing, augmenting, and chunking raw data into suitable formats for model consumption.
ETL (Extract, Transform, Load) pipelines.
Data Storage:
Object Storage: Scalable, cost-effective storage for large volumes of unstructured data (AWS S3, Google Cloud Storage, Azure Blob Storage).
Data Warehouses/Lakes: For structured and semi-structured data, enabling analytics and complex queries (Snowflake, Databricks Lakehouse, Google BigQuery).
Vector Databases: Highly specialized databases designed to efficiently store and query high-dimensional vector embeddings. Critical for fast similarity searches in RAG and semantic search applications (Pinecone, Weaviate, Milvus, Qdrant).
Knowledge Bases & Document Stores: The structured and unstructured data repositories that RAG systems retrieve information from (e.g., internal company wikis, documentation, CRM data).
Data Labeling Platforms: Services and tools for human annotation and labeling of data, crucial for supervised fine-tuning.
Data Governance & Security: Implementing policies, tools, and processes for data quality, privacy (e.g., GDPR, HIPAA compliance), access control, and lineage.
Examples: AWS S3, Google Cloud Storage, Pinecone, Apache Spark, Snowflake, custom document stores, vast web datasets.
Layer 1: Infrastructure Layer
Purpose: This is the foundational layer providing the raw compute, storage, and networking resources required to power all layers above it. It's the physical and virtual backbone of the entire GenAI tech stack.
Key Components & Responsibilities:
Compute Hardware:
GPUs (Graphics Processing Units): Essential for the parallel processing capabilities needed for deep learning model training and high-performance inference (e.g., NVIDIA A100s, H100s, L40S).
TPUs (Tensor Processing Units): Google's custom ASICs optimized specifically for machine learning workloads.
CPUs: For general-purpose computation, data preprocessing, and orchestrating workloads.
Cloud Platforms: Provide scalable, on-demand access to compute, storage, and managed services.
Amazon Web Services (AWS)
Google Cloud Platform (GCP)
Microsoft Azure
(Potentially on-premise data centers for specific enterprise needs).
Networking: High-bandwidth, low-latency network infrastructure for efficient data transfer between compute instances and storage.
Operating Systems: Typically Linux distributions (Ubuntu, CentOS, etc.) running on servers.
Virtualization / Container Orchestration:
Docker: For packaging applications and their dependencies into portable containers.
Kubernetes: For orchestrating, automating deployment, scaling, and managing containerized applications across clusters of machines. This is vital for managing distributed training and inference workloads.
Examples: NVIDIA GPUs, AWS EC2 instances, Google Compute Engine, Azure Kubernetes Service (AKS), Docker.
Why Understanding This Stack is Your Superpower
Knowing this 5-layer Generative AI Tech Stack isn't just for textbooks; it's your personal blueprint for success in the AI era. Here's why getting a handle on it is so important:
For Tech Professionals (like ML Engineers, Data Scientists, and Developers): This structure helps you pinpoint exactly what skills you need to learn. You can specialize in hot areas like LLMOps or Vector Databases, and clearly see how your work fits into the bigger GenAI picture. It truly empowers you to build, fine-tune, and launch cutting-edge AI systems.
For Product & Business Leaders: This clear view gives you the insights to make smart decisions—like whether to build AI features in-house or buy them. You'll better understand what's technically possible, how to budget effectively, and how to spot truly game-changing AI product ideas that hit market needs.
For Anyone in Tech: It turns Generative AI from a mysterious "black box" into a clear, understandable landscape. This knowledge lets you engage with GenAI strategically, whether you're hands-on building, managing projects, or simply figuring out how to use its incredible power.
What's Next?
The Generative AI journey is just beginning, and with a clear understanding of its underlying architecture, you're now better equipped to shape its future.
I'll be sharing more insights into the practical side of GenAI in upcoming posts.