

1. The Breaking Point: When RNNs Hit the Wall
For years, sequence modeling was ruled by RNNs and LSTMs. They were the go-to models for text, speech, and time-series data, anything where order mattered.
The idea behind them was simple but clever: process data one step at a time, and pass information forward through a hidden state. This way, the model could “remember” previous inputs as it read new ones.
It worked well for short sequences. But the cracks appeared quickly.
The Real Problems
1. Vanishing/Exploding Gradients - the famous one everyone talks about. But here’s what matters practically: Even with gradient clipping and LSTMs, you’re still fighting an uphill battle. Information from token 1 has to survive 100+ sequential transformations to influence token 100. That’s a game of telephone with exponential decay.
2. Sequential Bottleneck - this is the killer. Every step waits for the previous one. Your GPU sits there, mostly idle, processing one token at a time. It’s like having a 100-lane highway but being forced to drive single-file.
3. The Hidden State Compression Problem- here’s the intuition nobody tells you:
Imagine I tell you a story and ask: “Now summarize everything important in exactly 512 numbers.” Then I add more story. “Okay, still 512 numbers. Don’t forget the beginning!”
That’s what we asked RNNs to do.
LSTMs added “gates” - like giving you permission to forget certain things. Better, but still fundamentally a lossy compression game.
The Insight That Changed Everything
In 2014, Bahdanau introduced attention for neural machine translation. The key insight wasn’t the math - it was the question:
“Why compress the entire source sentence into one vector when the decoder can just look back and grab what it needs?”
It’s the difference between:
Taking notes on a book, then writing an essay from memory (RNN)
Writing an essay with the book open, referencing specific passages (Attention)
But they still used RNNs to process the sequence sequentially.
In 2017, Vaswani et al. asked the radical question:
“What if we throw out recurrence entirely and use only attention?”
That paper “Attention Is All You Need” became the most cited AI paper of the decade.
2. Architecture: Self-Attention Under the Hood
Let me show you what actually happens inside a Transformer, with the intuition first, math second.
2.1 The Core Idea: Attention as Database Lookup
Think of self-attention as a differentiable database query.
Every token in your sequence is simultaneously:
A query asking: “What information do I need?”
A key announcing: “I contain this type of information”
A value holding: “Here’s my actual content”
When processing the word “bank” in “I withdrew money from the bank”, the token:
Queries for context about transactions, finance
Keys from nearby tokens like “money” and “withdrew” light up
Values from those tokens flow into “bank”’s new representation
The genius: every token queries every other token simultaneously.
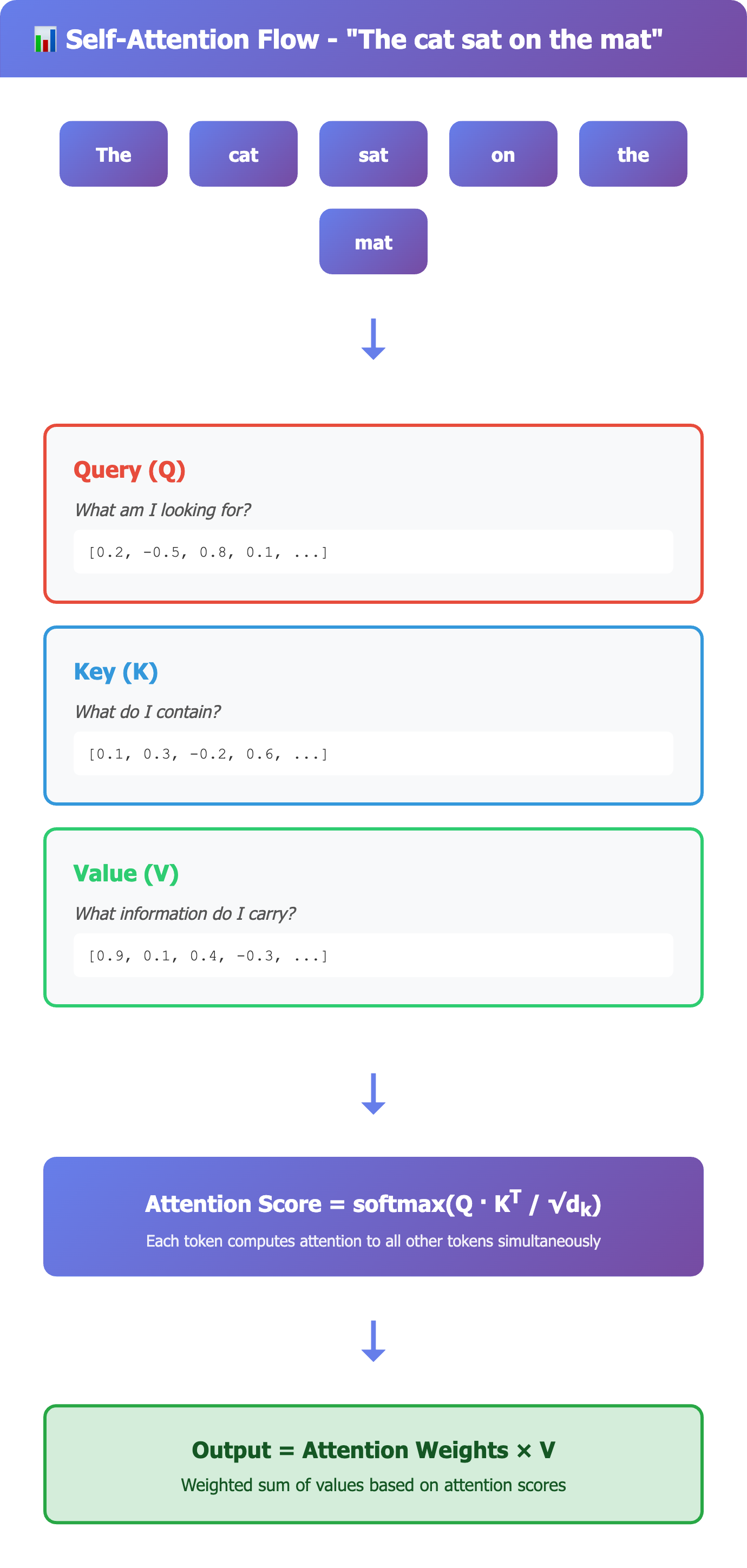
2.2 The Math (Now That You Get It)
For each token, we create three vectors via learned projections:
Query (Q): What am I looking for? Key (K): What do I contain?
Value (V): What information do I carry?
Compute relevance scores between all query-key pairs:
Score(Q_i, K_j) = Q_i · K_j
Scale to prevent saturation (critical for training stability):
Scaled Score = (Q_i K_j^T) / √d_k
Why divide by √d_k? Because dot products grow with dimensionality. Without scaling, softmax gets extreme values (0.00001, 0.00001, 0.99998) instead of smooth distributions. This kills gradient flow.
Apply softmax to get attention distribution:
Attention Weights = softmax(QK^T / √d_k)
Compute weighted sum of values:
Self-Attention(Q, K, V) = softmax(QK^T / √d_k)V
All tokens processed in parallel, one massive matrix multiplication.
2.3 Visual: What Attention Actually Looks Like
Input: “The cat sat on the mat”
Token: “sat”
├─ High attention to: “cat” (subject), “mat” (location)
├─ Medium attention to: “on”, “the”
└─ Low attention to: “The” (first token)
Token: “mat”
├─ High attention to: “sat” (action), “on” (relation)
├─ Medium attention to: “the” (determiner)
└─ Low attention to: “The”, “cat”
Each token builds a new representation by pulling information from relevant tokens, weighted by attention scores.
2.4 Multi-Head Attention: Why One Attention Isn’t Enough
Here’s the non-obvious insight: different types of relationships matter simultaneously.
Consider “The chef who runs the restaurant cooked the meal”
You need to track:
Syntactic structure: “who” refers to “chef”, not “restaurant”
Semantic roles: “chef” is the agent, “meal” is the bject
Long-range dependencies: “cooked” connects to “chef” across 5 words
Local context: “the restaurant” is a noun phrase unit
Single attention can’t capture all these patterns optimally.
Solution: Run h attention operations in parallel (typically 8-16 heads).
MultiHead(Q,K,V) = Concat(head_1, ..., head_h)W^O
where head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
Each head learns different relationship patterns:
Head 1: Subject-verb relationships
Head 2: Noun-modifier pairs
Head 3: Long-range dependencies
Head 4: Positional/sequential patterns
...and so on

2.5 Positional Encoding: Teaching Order Without Recurrence
Problem: Self-attention is permutation-invariant. “Dog bites man” and “Man bites dog” produce identical attention patterns.
Solution: Inject position information directly into embeddings.
The original paper used sinusoidal encodings:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
Why sinusoids? Two clever properties:
Relative positions: PE(pos+k) can be expressed as a linear function of PE(pos)
Unbounded length: Works for any sequence length, no training needed
Modern models often use learned positional embeddings (GPT) or rotary embeddings (RoPE in LLaMA) which have better extrapolation properties.
3. Why This Architecture Won
Let me tell you what actually mattered for Transformers’ success and it’s not what most people emphasize.
Parallelization: The GPU Unlock
RNN/LSTM:
Step 1: Process token 1 [GPU: 5% utilized]
Step 2: Process token 2 [GPU: 5% utilized]
Step 3: Process token 3 [GPU: 5% utilized]
...
Step 512: Process token 512 [GPU: 5% utilized]
Transformer:
Step 1: Process ALL 512 tokens simultaneously [GPU: 95% utilized]
This isn’t just faster it’s 2-3 orders of magnitude faster for long sequences. This is what made GPT-3 (175B parameters) feasible to train.
Global Context: See Everything, Attend to What Matters
RNNs forced information through a bottleneck. Transformers let every token directly access every other token.
In “The trophy doesn’t fit in the suitcase because it’s too big”:
LSTM struggles to connect “it” → “trophy” across 7 tokens
Transformer directly computes attention between “it” and both “trophy” and “suitcase”
The model learns “big” + “doesn’t fit” → probably referring to trophy, not suitcase.
Engineering Beauty: Why Systems Engineers Love Transformers
Stateless: No hidden state to serialize/deserialize between steps
Cacheable: In autoregressive generation, previous token representations are cached (KV cache)
Analyzable: Attention weights are interpretable- you can visualize what the model “looks at”
Modular: Easy to swap encoders/decoders, add/remove layers, change attention patterns
4. The Complexity Trade-off (And Why We Accept It)
The O(n²) Elephant in the Room
Self-attention computes interactions between all pairs of tokens:
Sequence length 512: 262,144 interactions
Sequence length 2048: 4,194,304 interactions
Sequence length 8192: 67,108,864 interactions
Complexity: O(n² · d) time, O(n²) memory
For context: RNN is O(n · d²) - linear in sequence length, quadratic in dimension.
So why did we accept quadratic complexity?
Three reasons:
GPUs love matrix multiplication : O(n²) on a GPU is often faster than O(n) on a CPU
Most NLP tasks used short sequences (≤512 tokens) where n² wasn’t prohibitive
The performance gain was massive - quadratic cost, 10x better accuracy
Modern Solutions
When quadratic became a problem (long documents, DNA sequences, code):
Sparse Attention (Longformer, BigBird): Only attend to local neighbors + global tokens + random samples
Reduces complexity to O(n · k) where k << n
Loses some global context
Linear Attention (Performer, Linformer):
Approximate softmax(QK^T)V with lower-rank operations
O(n) complexity
Slight accuracy drop
FlashAttention (2022): Don’t change the algorithm , optimize GPU memory access patterns
Same O(n²) complexity
3x faster, 10x less memory
This is what powers 100K+ context windows today
5. Interview Deep-Dive: Questions That Matter
Q1. Why did RNNs struggle with long-term dependencies?
Surface answer: Vanishing gradients.
Deep answer: Sequential processing creates a gradient path of length n. Even with careful initialization and gating (LSTM), each step multiplies by a matrix. After 100+ steps, either:
Products converge to zero (vanishing)
Products explode (unbounded)
The gradient w.r.t. token 1 has to flow through 100+ matrix multiplications. Attention creates direct paths - gradient flows in O(1) steps regardless of distance.
Q2. What’s the intuition behind Q, K, V?
Analogy: Search engine.
Query (Q): Your search terms , what you’re looking for
Key (K): Document titles/metadata , what each document is about
Value (V): Document content , actual information you retrieve
You compute relevance (Q·K), rank results (softmax), and retrieve content (weighted V).
Every token is simultaneously searching and being searched.
Q3. Why divide by √d_k in scaled dot-product attention?
Surface answer: To prevent large dot products.
The real reason: Dot product magnitude grows with dimensionality.
If Q and K are unit-variance, Q·K has variance d_k. For d_k = 512, typical dot products are in range [-50, 50]. After softmax, you get extreme distributions: (0.00001, 0.99998, 0.00001)
This creates two problems:
Saturation: Softmax derivatives → 0, killing gradients
Instability: Small input changes cause massive output swings
Dividing by √d_k normalizes variance back to 1, keeping softmax in the “soft” regime where gradients are healthy.
Q4. How do Transformers enable parallel computation?
Key insight: Attention is a three-matrix multiplication problem.
Attention = softmax(QK^T / √d_k) · V
QK^T: (n × d) · (d × n) → (n × n) attention matrix
softmax: element-wise, fully parallelizable
Attention · V: (n × n) · (n × d) → (n × d) output
All token interactions computed in one batched operation. RNNs required n sequential steps.
Modern GPUs do matrix multiplication at 200+ TFLOPS . Transformers exploit this perfectly.
Q5. What’s the difference between encoder-only and decoder-only Transformers?
Encoder-only (BERT):
Bidirectional attention - each token sees past AND future
Good for: classification, NER, Q&A (understanding tasks)
Training: Masked language modeling (predict random masked tokens)
Decoder-only (GPT):
Causal attention - token i can only see tokens 1...i (via attention mask)
Good for: text generation, completion (generative tasks)
Training: Next token prediction (autoregressive language modeling)
Encoder-Decoder (T5, BART):
Encoder: bidirectional on input
Decoder: causal, cross-attends to encoder outputs
Good for: translation, summarization (seq2seq tasks)
Q6. What’s the main bottleneck of Transformers?
Training: Compute (O(n² · d) attention + O(n · d²) FFN) Inference: Memory for KV cache
At inference, we cache K and V for all previous tokens. For 8K context, 32 layers, d=4096: ~2GB per request. This is why “context length” is expensive - it’s mostly a memory problem.
Q7. Why do we need positional encoding?
Self-attention is a set operation - order-invariant.
Without positional info:
“Dog bites man” = “Man bites dog”
“Not bad” = “Bad not”
Positional encoding adds order signal directly to embeddings, so the model can learn position-dependent patterns.
Why not just use token position as a feature? Because:
Absolute position isn’t what matters - “third word” means nothing
Relative position matters more distance and direction between tokens
Sinusoidal encoding captures relative position implicitly via phase relationships
Q8. How do you handle sequences longer than training length?
Problem: Train on 512 tokens, inference on 2048 tokens.
Solutions:
Sinusoidal PE: Extrapolates naturally (original Transformer)
Learned PE: Interpolate embeddings (okay but degraded)
ALiBi: Bias attention by relative distance (no explicit encoding)
RoPE: Rotate Q,K based on position (used in LLaMA, best extrapolation)
Modern long-context models (32K, 100K+) use RoPE + careful finetuning on longer sequences.
The Bigger Picture
Transformers didn’t just improve NLP - they unified sequence modeling across domains.
Same architecture, different data:
Text → GPT, BERT, T5
Images → Vision Transformer (ViT)
Audio → Whisper, AudioLM
Video → VideoGPT, Phenaki
Molecules → AlphaFold (protein structures)
Code → Codex, GitHub Copilot
Multimodal → CLIP, Flamingo, GPT-4
The insight: Everything can be tokenized into sequences. And attention is a universal way to model relationships.
📚 References & Further Reading
Here are some high-quality papers, articles, and visual guides to explore if you want to go deeper:
🔹 Foundational Papers
Vaswani et al. (2017) – “Attention Is All You Need”, NeurIPS 2017
Bahdanau et al. (2014) – “Neural Machine Translation by Jointly Learning to Align and Translate”
Hochreiter & Schmidhuber (1997) – “Long Short-Term Memory”
https://www.bioinf.jku.at/publications/older/2604.pdf
🔹 Technical Deep Dives
🔹 Videos & Talks
Yannic Kilcher – “Attention Is All You Need – Paper Explained” (YouTube)
Andrej Karpathy – “Let’s build GPT from scratch” (YouTube, 2023)
DeepLearning.AI – “Transformers Explained” short course by Andrew Ng
What’s Next?
This post covered why Transformers emerged and what makes them tick.
Next in the series:
Post 2: Deep dive into attention mechanisms visualizing heads, understanding learned patterns
Post 3: Scaling laws and emergent abilities why bigger models suddenly get qualitatively smarter
Post 4: From Transformers to LLMs training objectives, instruction tuning, RLHF
Question for you: What was the “aha!” moment that made Transformers click for you? Drop a comment . I read every one.
If you found this valuable, share it with someone learning ML. This series is my attempt to document everything I wish I knew when I started building with Transformers.